
【DS検定攻略】「データサイエンス力③」を深掘り!因果関係とバイアスを徹底解説!
皆さん、こんにちは!データサイエンティスト検定合格を目指す旅、順調に進んでいますか?
今回は、DS検定の重要テーマ「データサイエンス力」の中でも、特に理解を深めておきたい「③」の内容をギュッと凝縮したスライドたちを順番に解説していきます。単なる知識の詰め込みではなく、「なぜそうなのか?」という本質を理解して、実践的なデータサイエンス力を身につけていきましょう!
まずは、目次スライドから見ていきましょう。
01 条件と事象の共起性・関係性を把握する ~アソシエーション分析の基本~
さて、最初の項目は「条件と事象の共起性・関係性を把握する」です。
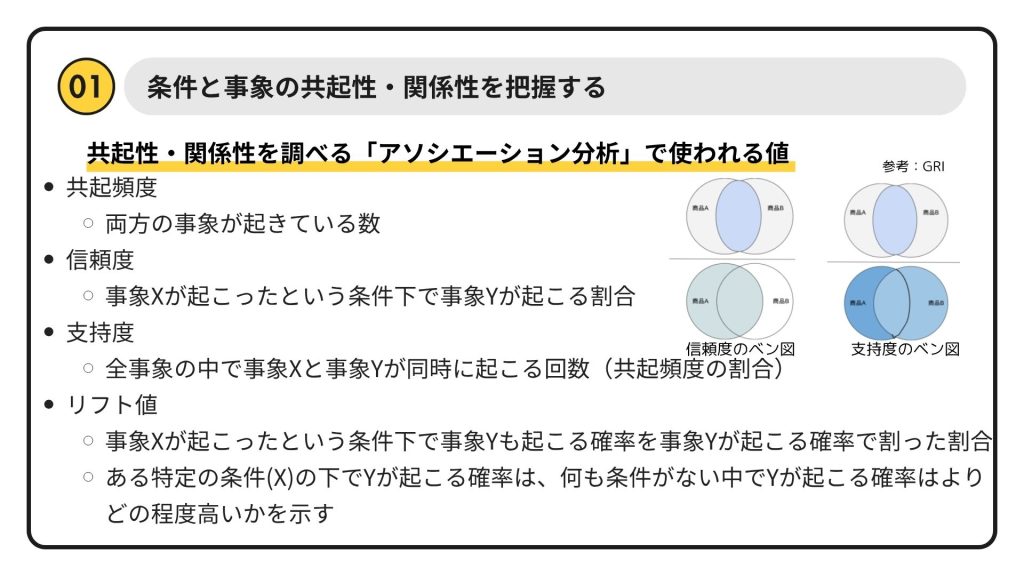
データサイエンスの入り口として、私たちはまず「何と何が一緒に起こりやすいのか」「どんな関係性があるのか」という点に注目します。これを調べるのが**「アソシエーション分析」**です。
スーパーのPOSデータで「おむつを買った人はビールも買う」という有名な話がありますよね?まさにこれこそが共起性・関係性の例です。スライドにもあるように、アソシエーション分析では以下のような指標を使って、その関係性の強さを数値で測ります。
- 共起頻度: 両方の事象が同時に起きる回数。シンプルに「よく一緒に起こるな」を数えます。
- 信頼度: 事象Xが起きたという条件で、事象Yが起こる割合。「おむつを買った人のうち、何%がビールも買うか」という見方ですね。
- 支持度: 全ての事象の中で、XとYが同時に起こる割合。全体の視点から見た、その関係性の「重要度」と言えます。
- リフト値: 事象Xが起きた場合にYが起こる確率が、何も条件がない場合にYが起こる確率と比べてどの程度高いかを示す値。これが1より大きければ、XとYに正の関係がある可能性が高いと判断できます。
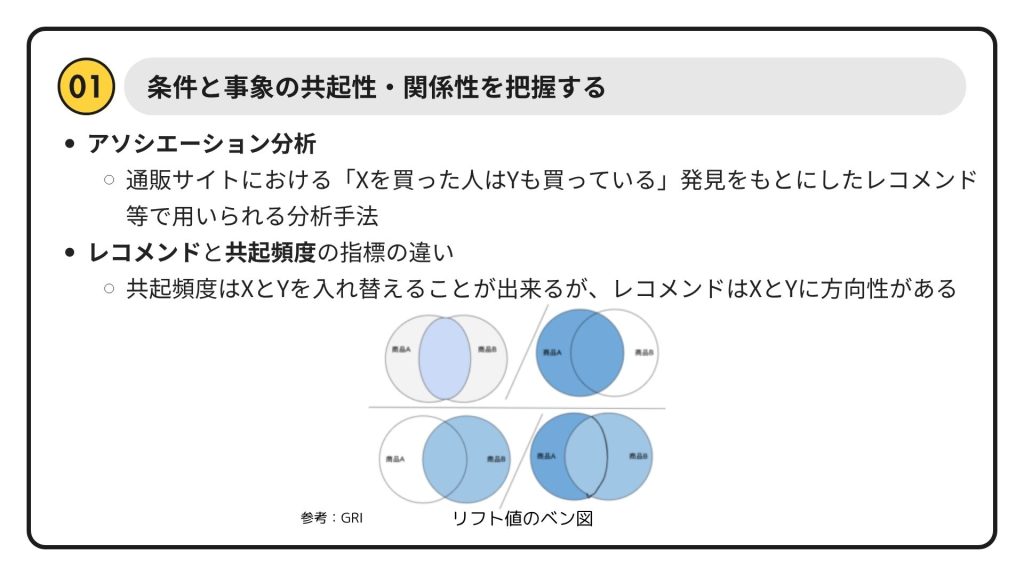
通販サイトのレコメンド機能も、このアソシエーション分析が基になっています。「この商品を買った人はこんな商品も買っています」という表示は、まさに共起性のデータから導き出されているわけですね。共起頻度はXとYを入れ替えても同じですが、レコメンドは「Xを買ったからYを勧める」というように、XからYへの方向性があるのが特徴です。
02 ランダム化比較実験の仕組み ~なぜランダムが重要なのか?~
次に、因果関係を解き明かすための強力なツール、「ランダム化比較実験(RCT)」の仕組みについて見ていきましょう。

特定の治療法や新しい教育ツールが、本当に目的とする効果をもたらしているのか?これを評価するために最も信頼性の高い方法が、このランダム化比較実験です。
鍵となるのは、「処置群(実験群)」と「対照群」へのランダムな割り当てです。例えば、新しいオンライン教育ツールが数学の成績に与える効果を調べたい場合を考えてみましょう。
- 研究者は学生をランダムに2つのグループに分けます。
- 一方は新しいツールを使う「処置群」。もう一方は従来の学習方法を続ける「対照群」。
なぜランダムに分けるのでしょうか?それは、**「他の要因(例えば、学生の学習意欲や背景など)が結果に与える影響を平均化し、ツール自体の効果をより正確に測定できる」**からです。ランダムに割り当てることで、両グループの背景にある要因(学力、家庭環境、やる気など)が平均的に揃うことが期待できるため、結果の違いが「ツールの効果」によるものだと考えやすくなるのです。

逆に、もし「間違った実験計画」をしてしまうとどうなるでしょう?
例えば、「新しい食生活プログラムが健康に与える影響」を評価する研究で、「プログラムに興味を示した人を対照群、興味を示さなかった人を処置群」としたら?これでは、プログラムに参加を希望した人はもともと健康意識が高いなど、プログラム自体以外の背景要因が結果に影響を及ぼしてしまう可能性があります。これではプログラムの効果を正しく評価できませんよね。
まとめると、データ分析における「選択バイアス」や「潜在的な交絡因子」を管理するには、ランダム化された実験を行うことが基本になります。これこそが、信頼性の高い因果関係を導き出すための重要なステップなのです。
03 因果関係を推定したい場合、交絡因子の考慮が重要 ~「本当の原因」を見抜く力~
因果関係を突き止める!これはデータサイエンスの醍醐味の一つですが、ここには落とし穴もあります。それが「交絡因子」です。
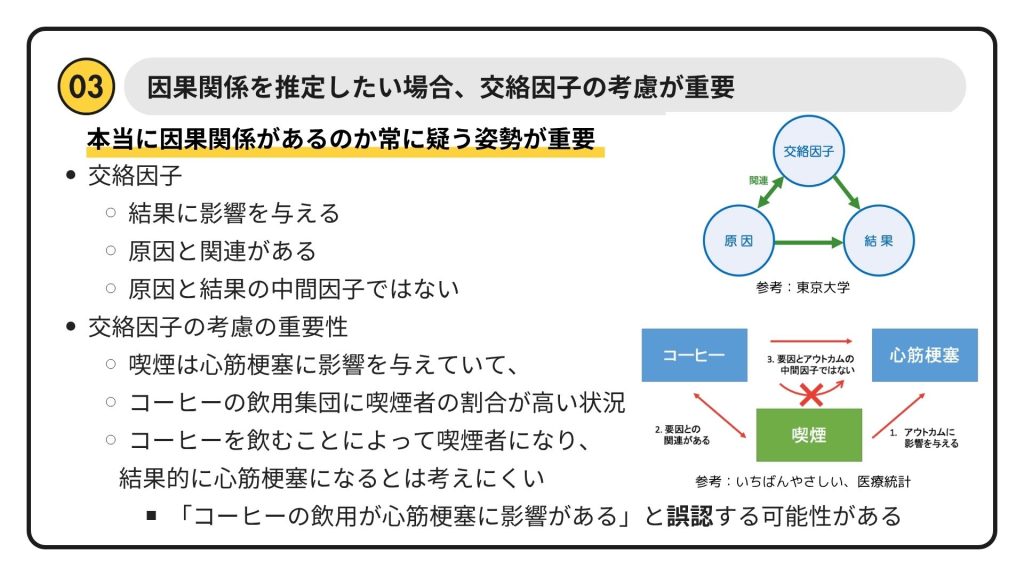
スライドの冒頭に「本当に因果関係があるのか常に疑う姿勢が重要」とありますが、これはデータサイエンティストにとって最も大切な心構えの一つです。
「交絡因子」とは、簡単に言うと、原因と結果の両方に影響を与え、その関係性を曖牲(ぎせい)にしてしまう第三の要因のことです。
- 交絡因子の特性:
- 結果に影響を与える
- 原因と関連がある
- 原因と結果の中間因子ではない(←ここが重要!)
スライド右上の図を見てください。原因と結果の間に、隠れた「交絡因子」が影響を及ぼしているのが分かりますね。
具体的な例として、「コーヒーの飲用が心筋梗塞に影響がある」という一見ありそうな話を見てみましょう。
- 「コーヒーの飲用集団に喫煙者の割合が高い状況」という場合、コーヒーを飲むことで心筋梗塞になるのではなく、喫煙習慣が原因で心筋梗塞になっている可能性が考えられます。
- つまり、このケースでは「喫煙」が交絡因子となり、「コーヒーの飲用が心筋梗塞に影響がある」と誤認する可能性があるのです。コーヒー自体が悪者ではないのに、喫煙のせいで冤罪になってしまう、というわけですね。
データ分析を行う際には、このように因果関係を見誤らせる「隠れた要因」がないかを常に考え、慎重に分析を進める必要があります。
04 分析対象を定める段階で選択バイアスが生じる可能性 ~データの偏りを見抜く目~
最後の項目は「分析対象を定める段階で選択バイアスが生じる可能性」です。これは、私たちがデータを得る最初の段階で、すでに結果を歪めてしまう危険性があるという重要な注意点です。

「バイアス」という言葉は、偏りや先入観を意味します。データ分析におけるバイアスは、結果の信頼性を大きく損ねる可能性があるため、細心の注意が必要です。
スライドでは、特に3つの選択バイアスが挙げられています。
-
選択バイアス① 脱落バイアス: 例えば、あるプログラムの参加者の効果を測定している途中で、体調を崩した人や、効果が出なかった人が途中で参加をやめてしまうケースです。最終的に残ったのは「健康な人」や「効果が出ている人」だけになり、あたかもプログラム全体に大きな効果があったかのように見えてしまう可能性があります。
-
選択バイアス② 欠測データバイアス: アンケートなどで、特定の質問に答えてくれる人とそうでない人の間で、背景や傾向に違いがある場合です。例えば、ネガティブな経験をした人は回答を避ける傾向がある、といった状況が考えられます。この偏りによって、データ全体の実態を正しく反映できないことがあります。
-
選択バイアス③ 自己選択バイアス: 治験やプログラム参加者の募集において、「健康に自信がある人」や「特定の疾患に関心がある人」など、参加者の意思によって集団に偏りが生じるケースです。参加者自身が「選び取った」結果として、無作為に抽出された集団とは異なる特性を持つことになり、結果が一般化しにくくなります。
これらの選択バイアスは、私たちが意図せずとも発生してしまう可能性があります。データを収集する段階から、どのような偏りが生じる可能性があるのかを予測し、できる限りそれを回避するための計画を立てることが、正確な分析の第一歩となります。
いかがでしたでしょうか?「データサイエンス力③」は、因果関係の正しい理解と、データ収集・分析におけるバイアスの回避という、データサイエンティストにとって非常に重要な「思考の軸」を養うための項目ばかりです。
これらの知識をしっかりと身につけて、DS検定合格、そしてその先のデータサイエンティストとしての活躍を目指していきましょう!


コメント